Automation-friendly framework for Continuous Testing
Automation-friendly framework for Continuous Testing


 Automation-friendly framework for Continuous Testing
Automation-friendly framework for Continuous Testing
Resource Monitoring ServiceA frequent task for tests is to monitor a target server's health. The monitoring service collects data from those remote servers. The following sources are supported:
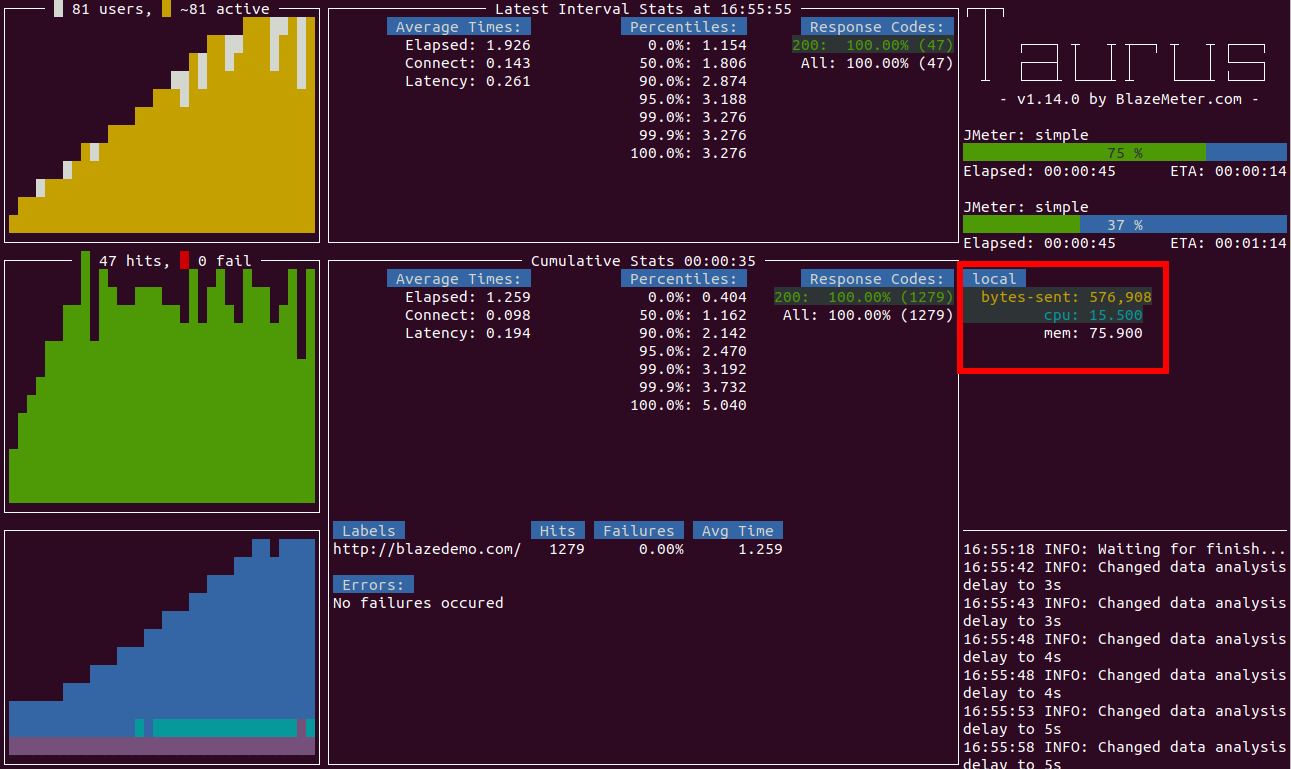
Local Monitoring StatsThis service collects local health stats from the computer running Taurus. It is enabled by default. Following metrics are collected locally:
If you want to use only your metrics, please look into merging rules. For example, if you want to see only specific metrics, use ~ like in the example below. You can also define whether you need logs for local monitoring by using the logging option. services: - module: monitoring ~local: - interval: 20s # polling interval logging: True # local monitoring logs will be saved to "local_monitoring_logs.csv" in the artifacts dir metrics: - cpu - disk-space - engine-loop Sidebar WidgetOnce you have resource monitoring enabled, you'll be presented with a small sidebar widget that informs you about the latest data from your monitoring agents:
The widget will possibly not display all the metrics for a very long list, that's a limitation of screen height. :) GraphiteGraphite data source uses graphite The Render URL API to receive metrics. In this example you can see usage optional server label, timeout for graphite answers, interval between requests and interesting graphite data range definition with parameters from/until. You can also define, whether you need logs for Graphite monitoring via logging option. services: - module: monitoring graphite: - address: 192.168.0.38 interval: 5s from: 100s until: 1s timeout: 2s logging: True # those logs will be saved to "Graphitelogs_192.168.0.38.csv" in the artifacts dir metrics: - store.memUsage - test.param1 - address: local_serv:2222 label: test_serv metrics: - production.hardware.cpuUsage - groupByNode(myserv_comp_org.cpu.?.cpu.*.value, 4, 'avg') ServerAgent (deprecated)ServerAgent was a small Java application that collected server health stats and made them accessible through network connection. To use it, you need to install and launch ServerAgent on each of your target servers and then specify metrics to collect under services item. You can also define, whether you need logs for ServerAgent via logging option. For example: services: - module: monitoring server-agent: - address: 192.168.0.1:4444 label: target-server # if you specify label, it will be used in reports instead of ip:port interval: 3s # polling interval logging: True # those logs will be saved to "SAlogs_192.168.0.1_4444.csv" in the artifacts dir metrics: - cpu - disks - memory |
On this page:
Quick Links: |